
The argument over lakehouse versus warehouse often sounds neat and theoretical, especially in vendor presentations and conference talks. In real organizations, however, the debate quickly turns into missed deadlines, budget overruns, and executives questioning why basic reports still feel unreliable. Many companies begin with good intentions, but when cost pressure dominates early decisions, they hire the lowest bidder who promises that one architecture will solve everything. Building a data warehouse, though, is closer to city planning than a cosmetic renovation, and shortcuts almost always surface later.
For organizations that care about building a data warehouse to support analytics and AI over the long term, the real question is not whether a lakehouse or a warehouse is better. The more important question is how different data components should work together. A hybrid setup that combines a curated warehouse, a flexible data lake, and shared data models often looks messy on diagrams. Yet this “Frankenstein” picture reflects how data actually flows across teams, products, and analytical use cases.
Why the Lakehouse vs Warehouse Debate Misses the Point
The lakehouse concept promises simplicity by merging the flexibility of a data lake with the structure of a data warehouse. In theory, this sounds efficient. In practice, most organizations still need different rules for different kinds of data. Financial reporting, regulatory metrics, and executive dashboards require strict definitions and stability. Exploratory analytics, event logs, and experimental machine learning features require flexibility and raw access.
A single structure rarely satisfies both needs equally well. When teams force all workloads into one design, trade-offs appear quickly. Either governance becomes too loose for trusted reporting, or flexibility disappears for experimentation. Mature data teams recognize that the debate itself is a distraction. The real work lies in deciding where structure is essential and where freedom adds value.
Why Vendors Push Simple Stories
Vendors often promote tidy architectural stories because they are easier to sell. A single platform with one storage layer and one query engine sounds safe to non-technical stakeholders. Unfortunately, simplicity at the slide level often hides complexity at the operational level. Once real data volumes, real users, and real compliance requirements arrive, the promised simplicity shifts into internal workarounds.
Teams are then left managing edge cases, custom pipelines, and manual fixes that were never part of the original pitch. Over time, these hidden efforts cost far more than a more thoughtful design would have from the start.
The Hidden Bill Behind the Lowest Bidder
The lowest bidder often wins by telling a comforting story. One storage layer, one tool, and one language that everyone can use. It feels efficient and budget-friendly. The problem is that this approach usually ignores how costs grow over time.
Research consistently shows that many infrastructure leaders now look to AI primarily as a way to reduce expenses, yet still struggle with cost discipline in cloud and data platforms. A well-known survey by Gartner found that more than half of infrastructure and operations leaders see cost optimization as their main reason for adopting AI. This pressure makes all-in-one promises especially tempting, even when they push real costs into the future.
Financial Drift and Technical Debt
When a low-cost vendor promises that a lakehouse will “scale later,” the real risk is not just the initial build. Over time, over-provisioned compute, inefficient queries, and surprise data transfer fees start to accumulate. Manual clean-up becomes routine. Internal teams spend increasing amounts of time keeping the platform usable instead of improving it.
Technical debt grows alongside financial waste. Warehouses built without strong dimensional modeling drift away from business reality. Column definitions change quietly. Metric logic is duplicated across reports. Lineage documentation falls out of sync. By the time leadership notices inconsistent numbers across dashboards, the cheapest option has often become the most expensive fix.
Why the Hybrid “Frankenstein” Architecture Works
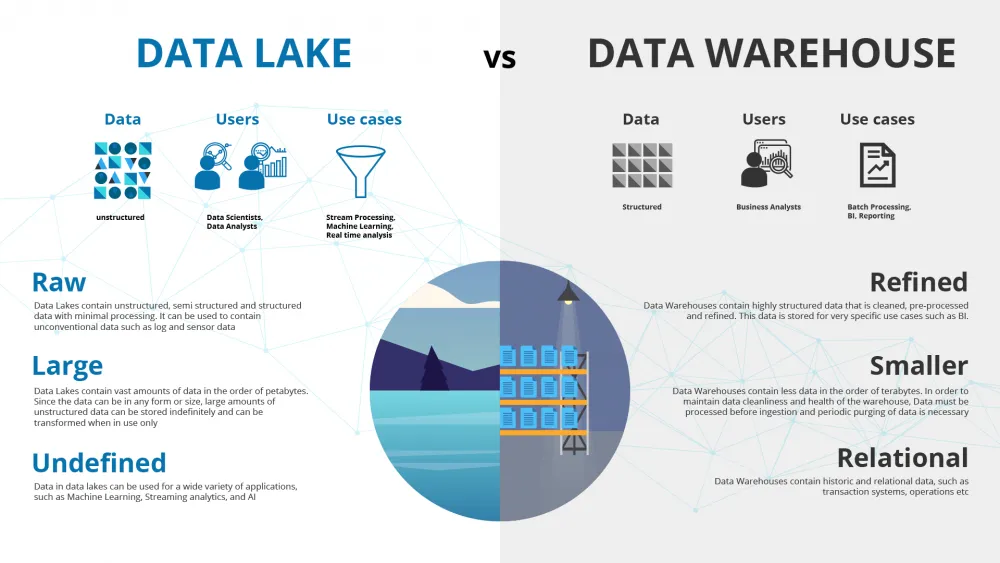
A hybrid data architecture accepts a basic truth about analytics and AI. Different questions require different data shapes. A curated data warehouse excels at audited metrics, financial reporting, and daily management views. A data lake is ideal for raw logs, semi-structured feeds, and long-term historical storage. Between them, shared data models or feature tables can serve machine learning and near-real-time use cases.
Although this setup looks complex, it mirrors how data actually evolves. Mature teams deliberately choose where data lives and why. They decide which datasets deserve strict contracts and which should remain flexible. This approach reduces friction rather than creating it.
Evidence from Mature Data Organizations
Industry research supports this mixed approach. PwC has highlighted in its cloud business surveys that leading organizations combine modernization with explicit governance and cost controls. Instead of hoping a single vendor stack will balance price and performance, they design for accountability from the start.
Engineering consultancies such as N-iX observe similar patterns in practice. Organizations that invest in building a data warehouse as a stable core, then attach lakes and domain-specific stores around it, are better positioned to support evolving product and AI demands. They adapt instead of rebuilding every few years.
The Real Price Gap Between Junior and Senior Design
Low bids often look attractive because the math seems simple. Two mid-level engineers with lower day rates appear cheaper than one senior architect. This calculation ignores the cost of experience.
The Stack Overflow Developer Survey consistently shows that senior engineering leaders earn significantly more than mid-level staff. This reflects the market’s understanding that experience reduces risk in complex systems. In data platforms, that value appears in what never goes wrong.
A well-designed warehouse does not require a rebuild after two years. A well-governed lake does not become an unusable dumping ground. A thoughtful data model evolves without breaking every downstream report. These outcomes rarely show up in initial estimates, but they dominate long-term cost.
Where Hidden Costs Actually Appear
Organizations that choose cheap designs often pay later through repeated migrations, constant firefighting, and lost opportunities. Pipelines built with shortcuts fail as soon as the business adds new products or acquisitions. Engineers spend time patching instead of innovating. Analysts lose trust in numbers and stop using data to guide decisions.
These costs are difficult to track, but they directly affect growth, speed, and confidence in analytics. Over time, they far exceed the savings from a lower initial bid.
Commissioning a Hybrid Architecture That Lasts
A hybrid architecture does not have to be chaotic. It needs clear intent and ownership. Leaders can start by asking for a simple map of the data landscape that explains which systems answer which questions. They can request clear contracts for core metrics and a transparent cost model that shows how spending will scale with usage.
Just as important is a realistic failure plan. Understanding what happens when pipelines break, how issues are detected, and who owns fixes reveals how mature a design really is. These discussions separate teams that think long term from those focused only on initial delivery.

Conclusion: Designing the Right Hybrid Instead of Choosing Sides
The lakehouse versus warehouse debate often distracts from what actually matters. For organizations serious about AI and analytics, the central question is who designs the hybrid system and how thoughtful that design is. One-size-fits-all promises usually delay costs rather than eliminate them.
A carefully planned mix of data lake, data warehouse, and domain-specific stores reflects how data truly behaves inside growing organizations. When informed by senior expertise and grounded in clear contracts and cost awareness, this hybrid “Frankenstein” becomes a strength rather than a liability. It provides a stable foundation for building a data warehouse that supports the business instead of slowing it down.
FAQS
What is the main difference between a data warehouse and a lakehouse?
A data warehouse focuses on structured, curated data for reporting, while a lakehouse combines data lake flexibility with some warehouse features for mixed workloads.
Is a lakehouse better than a data warehouse?
Not necessarily. A lakehouse works well for flexibility, but many organizations still need a data warehouse for trusted metrics and governance.
Why do many companies choose a hybrid architecture?
Hybrid architectures allow companies to store raw data in a lake, curated data in a warehouse, and serve analytics and AI use cases more effectively.
Can a hybrid data architecture increase costs?
If designed poorly, yes. When planned correctly, a hybrid setup can actually reduce long-term costs by placing data in the right system.
Why do low-cost vendors often cause long-term problems?
Low-cost vendors may ignore data modeling, governance, and scaling needs, which leads to rework, higher cloud costs, and unreliable reporting later.
Is a data warehouse still relevant for AI and analytics?
Yes, a data warehouse provides clean, reliable data that is critical for analytics, reporting, and many AI use cases.
What role does a data lake play in modern data platforms?
A data lake stores raw, semi-structured, and historical data that supports exploration, experimentation, and advanced analytics.
Do all companies need a lakehouse?
No. Some companies benefit more from a warehouse-plus-lake setup rather than forcing everything into a single lakehouse platform.
How does senior architecture expertise reduce risk?
Experienced architects design systems that scale, avoid rework, and maintain data trust over time, saving cost in the long run.
What is the biggest mistake in choosing a data architecture?
Focusing on tools instead of long-term data flow, governance, and business needs is the most common and costly mistake.
For more
For more exclusive influencer stories, visit influencergonewild